Вдвое эффективнее, втрое больше памяти: Google представила новые TPU 8 поколения
Только что на конференции Google Cloud Next ’26 в Лас-Вегасе Google представила восьмое поколение собственных процессоров — Tensor Processing Units. Оба чипа разработаны в партнерстве с Google DeepMind и будут общедоступны позже в этом году как часть платформы AI Hypercomputer.
В отличие от предыдущих поколений, TPU 8 впервые разделен на два специализированных чипа с принципиально разными архитектурами: TPU 8t для тренировки моделей и TPU 8i для инференса. TPU 8t (кодовое название Sunfish, разработанный совместно с Broadcom) ориентирован на тренировку крупных моделей. Он масштабируется до 9 600 чипов в едином суперподе с 2 петабайтами общей высокопропускной памяти и достигает 121 эксафлопа производительности в формате FP4.
Новая архитектура межчиповых соединений позволяет Google с помощью фреймворков JAX и Pathways масштабироваться до более миллиона TPU в одном тренировочном кластере. Показатель производительности на ватт вырос вдвое по сравнению с предыдущим поколением Ironwood. Отдельная инновация — TPUDirect RDMA, обеспечивающая прямую передачу данных между памятью и сетевыми картами в обход CPU, существенно снижая задержки.
TPU 8i (кодовое название Zebrafish, разработанный совместно с MediaTek) оптимизирован для инференса и агентных нагрузок. Он масштабируется до 1 152 чипов в едином поде, достигает 11,6 эксафлопа производительности FP8 и содержит в три раза больше встроенной памяти SRAM по сравнению с предыдущей версией — для хранения больших KV-кэшей непосредственно на кристалле.
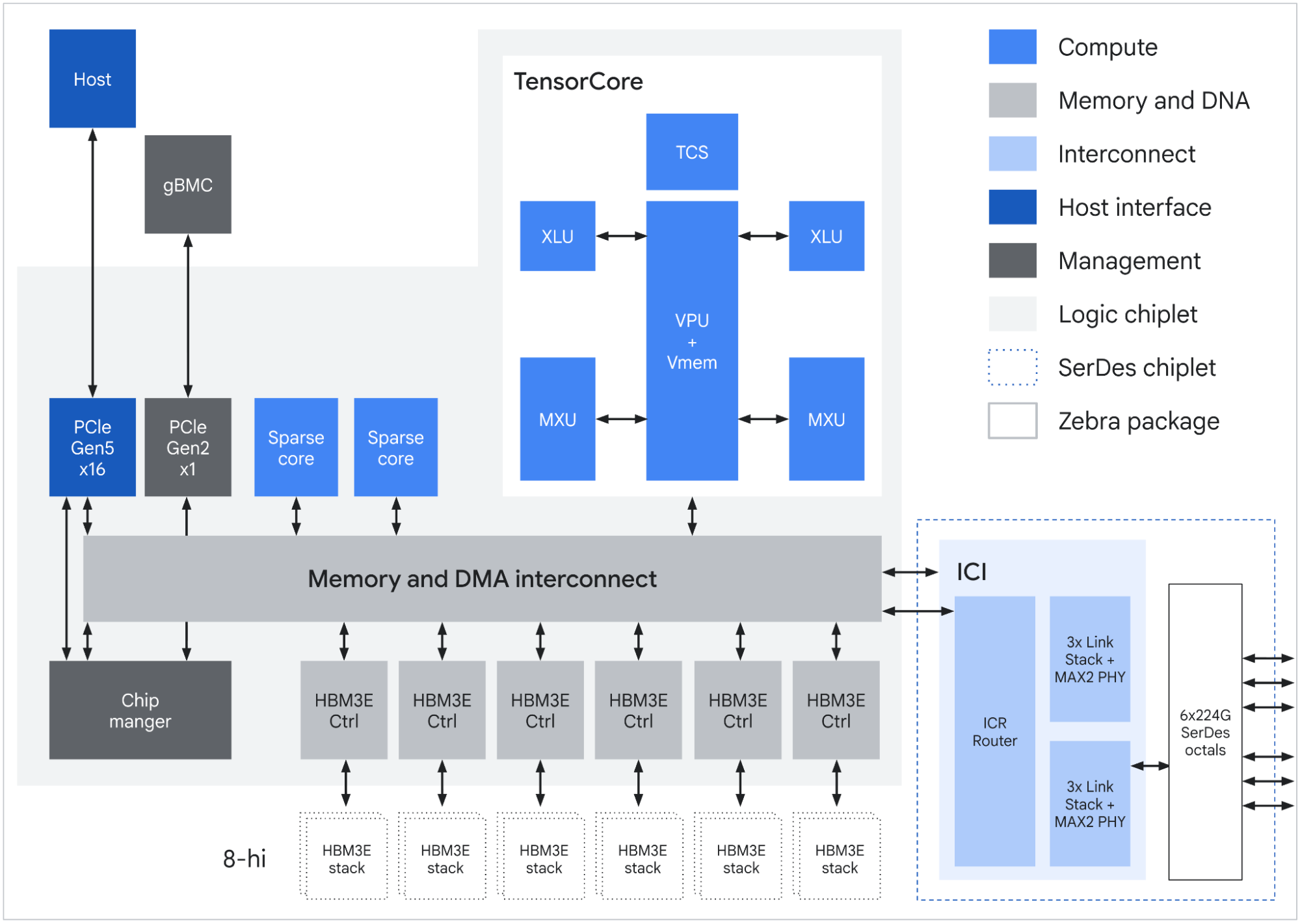
По данным Google, TPU 8i обеспечивает на 80% лучшую производительность на доллар по сравнению с Ironwood, что делает его пригодным для одновременного запуска миллионов агентов в промышленном масштабе. Оба чипа используют Axion ARM-процессор в качестве хоста и поддерживают жидкостное охлаждение.
Параллельно Google анонсировала сетевую инновацию Virgo Network — новую архитектуру для дата-центров, которая обеспечивает до 47 петабит в секунду пропускной способности и способна объединять более 134 000 чипов TPU 8t в единую тренировочную инфраструктуру. Новая система хранения Managed Lustre теперь обеспечивает 10 ТБ/с пропускной способности для TPU 8t через RDMA.
Стоит отметить, что Google ведет активную борьбу за рынок ИИ-ускорителей с NVIDIA. По данным аналитиков, Anthropic уже подписала соглашение на использование до миллиона TPU от Google, а Meta заключила многолетний многомиллиардный контракт на доступ к облачной TPU-инфраструктуре Google Cloud. Как мы писали ранее, именно на TPU обучается Gemini 3.1 Pro — модель, которая в феврале 2026 года заняла первое место в 12 бенчмарках среди конкурентов.
Google роздає 20 000 безплатних курсів з ШІ на Coursera для українців: як подати заявку
Источник: Google
Новость публикуется в партнерстве с?Вместе с Google Cloud Next 2026 открываются новые возможности — вместе с Cloudfresh они начинают работать на вас.
Cloudfresh 🌥️ — глобальный Google Cloud Premier Partner. Более 2 500 клиентов. Более 70 стран.
Next задаёт новый вектор: автономные агенты, ИИ и облачные инструменты, которые уже сегодня могут работать в вашем бизнесе.
От ИИ и безопасности до инфраструктуры и работы с данными — Cloudfresh 🌥️ превращают новые возможности Google Cloud в конкретные решения.
Обсудим ваши планы →
#GenerateTheReal✨
Схожі новини
